Aayush Neupane
Grad Student, MSCS. Looking for Summer Internship 2026
About me
I am a graduate student in Computer Science with a strong background in software, data, and machine learning engineering. Over the past few years, I have worked on projects that span from building large-scale data processing pipelines to deploying machine learning models in production environments. My work often sits at the intersection of software engineering and data science, designing reliable systems that can process, analyze, and learn from large and complex datasets.
At Smart Data Solutions, I engineered data pipelines integrating Java and Python components for processing scanned medical documents and applied NLP and deep learning models to automate information extraction. I have also worked on backend systems using Django, Celery, and Airflow, handling high-volume data storage and retrieval across SQL, NoSQL, and Redshift databases. Earlier, at Naamche, I contributed to full-stack and AI projects that combined LLMs, semantic search, and vector databases for real-time knowledge retrieval.
I am passionate about building scalable, data-driven systems that bridge the gap between infrastructure and intelligence. My interests include data engineering, distributed systems, and applied machine learning. I enjoy working in collaborative environments where I can contribute to both system design and model integration, continuously learning new tools and techniques to make data processing faster, smarter, and more reliable.
- Software Engineering
- Data Science and Machine Learning
- Data Engineering
- NLP, Programming languages, Software systems
Experience
- Conduct weekly labs on C/C++, Git, and Docker for 30+ undergraduate students; also grade assignments, in-class problems, and labs.
- Worked on information extraction from healthcare-related documents, including insurance claims and medical records. Performed data collection, cleaning, and model training for information extraction.
- Developed an intelligent medical record processing system to extract important information from medical records using models like LayoutLM and Large Language Models.
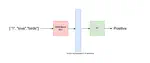
- Created chatbots using Large Language Models (LLMs) for real estate and university extension centers.
- Collected, cleaned, and indexed data in a vector database for implementing RAG-based framework, using tools like Scrapy, Metabase, and AWS Sagemaker.
- Developed API using FastAPI framework and implemented guardrails for chatbots.
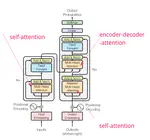
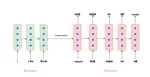
- Worked on NLP and learned about RNNs and Transformer-based models, focusing on attention mechanisms used by Transformers.
- Developed chatbots using the RASA framework.
- Managed software events and maintained software systems including LOCUS’s website and its online certification system.
- Developed and launched the online certification system used at LOCUS.
- Managed Azure account/virtual servers for deploying LOCUS products.
- Led a 10-day fellowship program to teach over 120 students software development practices.
Education
- Analysis of Algorithms
- Advanced Data Science
- Static Analysis
- Artificial Intelligence
- Data Science
- Database Management System
- Object Oriented Programming with C++
- Operating Systems
- Distributed Systems