RNN as an encoder
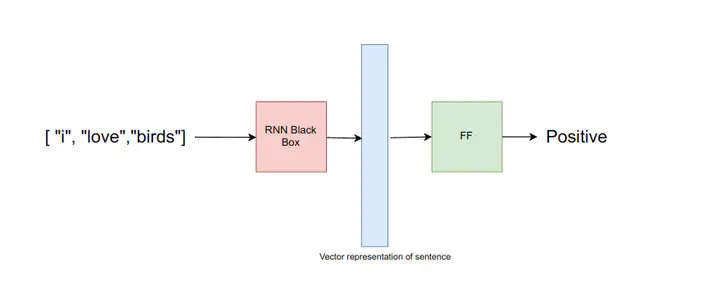
Recurrent Neural Networks (RNNs) are a type of neural network that makes it possible to analyze sequential data, such as text or time series data. They are called “recurrent” because they perform the same task for every element of a sequence, with the output being dependent on the previous computations.
RNN in the context of natural language processing can be best understood as.
RNNis a simple feed-forward neural network that is applied in the loop to each word in a sentence, while also adding the output of previous input generated bythesameRNN
Consider an example where you want to classify the sentiment of a sentence. For that we take the simplest possible approach, We use RNN as a feature extractor. We pass our sentence through the RNN which gives us the vector representation of the sentence. We use this vector representation of the sentence as input to the feed-forward neural network which has the no of outputs equal to the number of classes. we can however use only 1 output in case there are only two classes. A high value for this output will represent one class and a low value for this output will represent another class.
From the above image, we can see that RNN converts sentences into embedding, But we can’t give a sentence to the neural network so we convert each word in a sentence to word embedding and feed that to the neural network. We can also use Embedding layer in the PyTorch to train the word embedding along the way, Embedding layer can also be used to load pre-trained word embedding from word2vec or Glove . In this article we assume already have word embeddings for each word in a sentence.
import torch
import torch.nn as nn
# first argument represents number of sentence in a batch
# second argument represent number of word in a sentence
# third argument represent word embedding size
sentence_word_embeddings = torch.randn(1, 3, 20) # dummy sentence embedding
word_embedding_length = 20
rnn_hidden_size = 15
rnn = nn.RNN(
input_size=word_embedding_length,
hidden_size=rnn_hidden_size,
num_layers=1,
batch_first=True,
)
out, hn = rnn(sentence_word_embeddings)
print(out.shape)
Now we can discuss what are the parameters that we have to give while creating the RNN layer and what input to give to the RNN after creating and, what to expect as a output of the RNN layer.
Parameters for creating RNN layer
input_size
In our example of using RNN to encode the sentence
inputs_sizerepresents the word embedding size, each word in the all of the sentence has fixed length word embedding size,input_size.hidden_size
This is a hyperparameter in our network, we can try different values and see which works best for use. RNN is also a simple neural network so it has inputs and outputs, this represents the output size of
RNNnum_layers
RNNimplementation of the Pytorch is actually stackedRNNin which output from the oneRNNlayer is passed to the nextRNNlayer to produce final outputs,num_layersrepresent the number of stackedRNNunit we want to use in our networkbatch_first
This argument is not actually related to how RNN works, it is rather related to different deep learning frameworks. When
batch_firstis set to true, the first dimension in our input and output tensor represents abatchfirst example output of shape(1,3,15)will represent 1 sentence with 3 words and 15 is the embedding size of each word whenbatch_firstistrue
Inputs passed to the RNN (inputs,h0)
inputs
if we want to send a batch if sentences to the RNN the dimension of the input should be
(N,T,D)whereNrepresents the number of sentences,Trepresents the number of words in each sentence,Drepresents word embedding sizeinitial hidden state (h0)
RNNis a simple feed-forward neural network that is applied in the loop to each word in a sentence, while also adding the output of previous input generated bythesameRNN. But we don’t have any previous output in the first state to we need to give initial hidden state for the first-time step.The dimension of
h0is(num_layers,batch_size,hidden_size)we can initialize the initial hidden state for each sentence for each
RNNunit. The length of the vector of the initial hidden_state ishidden_sizebecause that’s what we feed back toRNNfrom the previous state of other time steps. Hence the dimension of the initial hidden state.
The output of the RNN Layer (out,h_n)
out, The output of the final layer for each word (N,T,D)
Each word passes through all the
RNNlayers (ifnum_layers>1) and produces final output, output contains final output of each word of each sentence hence the dimension(N,T,D).Nfor all sentences,Tfor each word,Dis thehidden_sizeof theRNNh_n, The hidden state with dimension=(num_layers,N,D)
Each sentence is passed through stacked RNN, After finishing a pass for each word in the sentence we can look at the output of each RNN unit. We do this for each sentence and this gives us
h_n
RNN complete picture
Note that there are only two fully connected neural networks, which is used in a loop 3 times, because the length of our sentence is 3
